Running Experiments
General Workflow
To run your own SKLL experiments via the command line, the following general workflow is recommended.
Get your data into the correct format
SKLL can work with several common data formats, all of which are described here.
If you need to convert between any of the supported formats, because, for example, you would like to create a single data file that will work both with SKLL and Weka (or some other external tool), the skll_convert script can help you out. It is as easy as:
$ skll_convert examples/titanic/train/family.csv examples/titanic/train/family.arff
Create sparse feature files, if necessary
skll_convert can also create sparse data files in .jsonlines, .libsvm, or .ndj formats. This is very useful for saving disk space and memory when you have a large data set with mostly zero-valued features.
Set up training and testing directories/files
At a minimum, you will probably want to work with a training set and a testing set. If you have multiple feature files that you would like SKLL to join together for you automatically, you will need to create feature files with the exact same names and store them in training and testing directories. You can specifiy these directories in your config file using train_directory and test_directory. The list of files is specified using the featuresets setting.
If you’re conducting a simpler experiment, where you have a single training file with all of your features and a similar single testing file, you should use the train_file and test_file settings in your config file.
Note
If you would like to split an existing file up into a training set and a testing set, you can employ the filter_features utility script to select instances you would like to include in each file.
Create an experiment configuration file
You saw a basic configuration file in the tutorial. For your own experiment, you will need to refer to the Configuration file fields section.
Run configuration file through run_experiment
There are a few meta-options for experiments that are specified directly to the
run_experiment command rather than in a configuration
file. For example, if you would like to run an ablation experiment, which
conducts repeated experiments using different combinations of the features in
your config, you should use the run_experiment --ablation option. A
complete list of options is available here.
Next, we describe the numerous file formats that SKLL supports for reading in features.
Feature files
SKLL supports the following feature file formats:
arff
The same file format used by Weka with the following added restrictions:
Only simple numeric, string, and nomimal values are supported.
Nominal values are converted to strings.
If the data has instance IDs, there should be an attribute with the name specified by id_col in the Input section of the configuration file you create for your experiment. This defaults to
id. If there is no such attribute, IDs will be generated automatically.If the data is labelled, there must be an attribute with the name specified by label_col in the Input section of the configuartion file you create for your experiment. This defaults to
y. This must also be the final attribute listed (like in Weka).
csv/tsv
A simple comma or tab-delimited format. SKLL underlyingly uses pandas to read these files which is extremely fast but at the cost of some extra memory consumption.
When using this file format, the following restrictions apply:
If the data is labelled, there must be a column with the name specified by label_col in the Input section of the configuration file you create for your experiment. This defaults to
y.If the data has instance IDs, there should be a column with the name specified by id_col in the Input section of the configuration file you create for your experiment. This defaults to
id. If there is no such column, IDs will be generated automatically.All other columns contain feature values, and every feature value must be specified (making this a poor choice for sparse data).
Warning
SKLL will raise an error if there are blank values in any of the columns. You must either drop all rows with blank values in any column or replace the blanks with a value you specify. To drop or replace via the command line, use the filter_features script. You can also drop/replace via the SKLL Reader API, specifically
skll.data.readers.CSVReaderandskll.data.readers.TSVReader.Dropping blanks will drop all rows with blanks in any of the columns. If you care only about some of the columns in the file and do not want to rows to be dropped due to blanks in the other columns, you should remove the columns you do not care about before dropping the blanks. For example, consider a hypothetical file
in.csvthat contains feature columns namedAthroughGwith the IDs stored in a column namedIDand the labels stored in a column namedCLASS. You only care about columnsA,C, andFand want to drop all rows in the file that have blanks in any of these 3 columns but do not want to lose data due to there being blanks in any of the other columns. On the command line, you can run the following two commands:$ filter_features -f A C F --id_col ID --label_col class in.csv temp.csv $ filter_features --id_col ID --label_col CLASS --drop_blanks temp.csv out.csv
If you are using the SKLL Reader API, you can accomplish the same in a single step by also passing using the keyword argument
pandas_kwargswhen instantiating either askll.data.readers.CSVReaderor askll.data.readers.TSVReader. For our example:r = CSVReader.for_path('/path/to/in.csv', label_col='CLASS', id_col='ID', drop_blanks=True, pandas_kwargs={'usecols': ['A', 'C', 'F', 'ID', 'CLASS']}) fs = r.read()
Make sure to include the ID and label columns in the usecols list otherwise
pandaswill drop them too.
jsonlines/ndj (Recommended)
A twist on the JSON format where every line is a
either JSON dictionary (the entire contents of a normal JSON file), or a
comment line starting with //. Each dictionary is expected to contain the
following keys:
y: The class label.
x: A dictionary of feature values.
id: An optional instance ID.
This is the preferred file format for SKLL, as it is sparse and can be slightly faster to load than other formats.
libsvm
While we can process the standard input file format supported by LibSVM, LibLinear, and SVMLight, we also support specifying extra metadata usually missing from the format in comments at the of each line. The comments are not mandatory, but without them, your labels and features will not have names. The comment is structured as follows:
ID | 1=ClassX | 1=FeatureA 2=FeatureB
The entire format would like this:
2 1:2.0 3:8.1 # Example1 | 2=ClassY | 1=FeatureA 3=FeatureC
1 5:7.0 6:19.1 # Example2 | 1=ClassX | 5=FeatureE 6=FeatureF
Note
IDs, labels, and feature names cannot contain the following
characters: | # =
Configuration file fields
The experiment configuration files that run_experiment accepts are standard
Python configuration files
that are similar in format to Windows INI files. [1]
There are four expected sections in a configuration file: General,
Input, Tuning, and Output. A detailed description of each
field in each section is provided below, but to summarize:
If you want to do cross-validation, specify a path to training feature files, and set task to
cross_validate. Please note that the cross-validation currently uses StratifiedKFold. You also can optionally use predetermined folds with the folds_file setting.Note
When using classifiers, SKLL will automatically reduce the number of cross-validation folds to be the same as the minimum number of examples for any of the classes in the training data.
If you want to train a model and evaluate it on some data, specify a training location, a test location, and a directory to store results, and set task to
evaluate.
If you want to just train a model and generate predictions, specify a training location, a test location, and set task to
predict.
If you want to just train a model, specify a training location, and set task to
train.
If you want to generate learning curves for your data, specify a training location and set task to
learning_curve. The learning curves are generated using essentially the same underlying process as in scikit-learn except that the SKLL feature pre-processing pipeline is used while training the various models and computing the scores.Note
Ideally, one would first do cross-validation experiments with grid search and/or ablation and get a well-performing set of features and hyper-parameters for a set of learners. Then, one would explicitly specify those features (via featuresets) and hyper-parameters (via fixed_parameters) in the config file for the learning curve and explore the impact of the size of the training data.
To ensure reliable results, SKLL expects a minimum of 500 examples in the training set when generating learning curves.
If you set probability to
True, the probabilities will be converted to the most likely label via anargmaxbefore computing the curve.
A list of classifiers/regressors to try on your feature files is required.
Example configuration files are available here under the california, iris, and titanic sub-directories.
General
Both fields in the General section are required.
experiment_name
A string used to identify this particular experiment configuration. When generating result summary files, this name helps prevent overwriting previous summaries.
task
What types of experiment we’re trying to run. Valid options are: cross_validate, evaluate, predict, train, learning_curve.
Input
The Input section must specify the machine learners to use via the learners field as well as the data and features to be used when training the model. This can be done by specifying either (a) train_file in which case all of the features in the file will be used, or (b) train_directory along with featuresets.
learners
List of scikit-learn models to be used in the experiment. Acceptable values
are described below. Custom learners can also be specified. See
custom_learner_path.
Classifiers:
AdaBoostClassifier: AdaBoost Classification. Note that the default base estimator is a
DecisionTreeClassifier. A different base estimator can be used by specifying anestimatorfixed parameter in the fixed_parameters list. The following additional base estimators are supported:MultinomialNB,SGDClassifier, andSVC. Note that the last two base estimators require setting an additionalalgorithmfixed parameter with the value'SAMME'.BaggingClassifier: Bagging Classification. Note that the default base estimator is a
DecisionTreeClassifier. A different base estimator can be used by specifying anestimatorfixed parameter in the fixed_parameters list. The following additional base estimators are supported:MultinomialNB,SGDClassifier, andSVC. Note that when usingSVCbase estimators, you may encounter errors if you have rare classes in your data.DummyClassifier: Simple rule-based Classification
DecisionTreeClassifier: Decision Tree Classification
GradientBoostingClassifier: Gradient Boosting Classification
HistGradientBoostingClassifier: Histogram-based Gradient Boosting Classifier. Requires dense feature array; sparse features will be automatically converted to dense when using this learner.
KNeighborsClassifier: K-Nearest Neighbors Classification
LogisticRegression: Logistic Regression Classification using LibLinear
MLPClassifier: Multi-layer Perceptron Classification
MultinomialNB: Multinomial Naive Bayes Classification
RandomForestClassifier: Random Forest Classification
RidgeClassifier: Classification using Ridge Regression
SGDClassifier: Stochastic Gradient Descent Classification
VotingClassifier: Soft Voting/Majority Rule classifier for unfitted estimators. Using this learner requires specifying the underlying estimators using the
estimator_namesfixed parameter in the fixed_parameters list. By default, this learner uses “hard” voting, i.e., majority rule. To use “soft” voting, i.e., based on the argmax of the sums of the probabilities from the underlying classifiers, specify thevoting_typefixed_parameter and set it to “soft”. The following additional fixed parameters can also be supplied in the fixed_parameters list:
estimator_fixed_parameterswhich takes a list of dictionaries to fix any parameters in the underlying learners to desired values,
estimator_param_gridswhich takes a list of dictionaries specifying the possible list of parameters to search for every underlying learner,
estimator_sampler_listwhich can be used to specify any feature sampling algorithms for the underlying learners, and
estimator_sampler_parameterswhich can be used to specify any additional parameters for any specified samplers.Refer to this example voting configuration file to see how these parameters are used.
Regressors:
AdaBoostRegressor: AdaBoost Regression. Note that the default base estimator is a
DecisionTreeRegressor. A different base estimator can be used by specifying anestimatorfixed parameter in the fixed_parameters list. The following additional base estimators are supported:LinearRegression,SGDRegressor, andSVR.BaggingRegressor: Bagging Regression. Note that the default base estimator is a
DecisionTreeRegressor. A different base estimator can be used by specifying anestimatorfixed parameter in the fixed_parameters list. The following additional base estimators are supported:LinearRegression,SGDRegressor, andSVR.BayesianRidge: Bayesian Ridge Regression. Requires dense feature array; sparse features will be automatically converted to dense when using this learner.
DecisionTreeRegressor: Decision Tree Regressor
DummyRegressor: Simple Rule-based Regression
ElasticNet: ElasticNet Regression
GradientBoostingRegressor: Gradient Boosting Regressor
HistGradientBoostingRegressor: Histogram-based Gradient Boosting Regressor. Requires dense feature array; sparse features will be automatically converted to dense when using this learner.
HuberRegressor: Huber Regression
KNeighborsRegressor: K-Nearest Neighbors Regression
Lars: Least Angle Regression. Requires dense feature array; sparse features will be automatically converted to dense when using this learner.
Lasso: Lasso Regression
LinearRegression: Linear Regression
LinearSVR: Support Vector Regression using LibLinear
MLPRegressor: Multi-layer Perceptron Regression
RandomForestRegressor: Random Forest Regression
RANSACRegressor: RANdom SAmple Consensus Regression. Note that the default base estimator is a
LinearRegression. A different base regressor can be used by specifying aestimatorfixed parameter in the fixed_parameters list. The following additional base estimators are supported:LinearRegression,SGDRegressor, andSVR.Ridge: Ridge Regression
SGDRegressor: Stochastic Gradient Descent Regression
TheilSenRegressor: Theil-Sen Regression. Requires dense feature array; sparse features will be automatically converted to dense when using this learner.
VotingRegressor: Prediction voting regressor for unfitted estimators. Using this learner requires specifying the underlying estimators using the
estimator_namesfixed parameter in the fixed_parameters list. The following additional fixed parameters can also be supplied in this list:
estimator_fixed_parameterswhich takes a list of dictionaries to fix any parameters in the underlying learners to desired values,
estimator_param_gridswhich takes a list of dictionaries specifying the possible list of parameters to search for every underlying learner,
estimator_sampler_listwhich can be used to specify any feature sampling algorithms for the underlying learners, and
estimator_sampler_parameterswhich can be used to specify any additional parameters for any specified samplers.Refer to this example voting configuration file to see how these parameters are used.
For all regressors except
VotingRegressor, you can also prependRescaledto the beginning of the full name (e.g.,RescaledSVR) to get a version of the regressor where predictions are rescaled and constrained to better match the training set. Rescaled regressors can, however, be used as underlying estimators forVotingRegressorlearners.
featuresets
List of lists of prefixes for the files containing the features you would like
to train/test on. Each list will end up being a job. IDs are required to be
the same in all of the feature files, and a ValueError will be raised
if this is not the case. Cannot be used in combination with
train_file or test_file.
Note
If specifying train_directory or test_directory, featuresets is required.
train_file
Path to a file containing the features to train on. Cannot be used in combination with featuresets, train_directory, or test_directory.
Note
If train_file is not specified, train_directory must be.
train_directory
Path to directory containing training data files. There must be a file for each featureset. Cannot be used in combination with train_file or test_file.
Note
If train_directory is not specified, train_file must be.
The following is a list of the other optional fields in this section in alphabetical order.
class_map (Optional)
If you would like to collapse several labels into one, or otherwise modify your
labels (without modifying your original feature files), you can specify a
dictionary mapping from new class labels to lists of original class labels. For
example, if you wanted to collapse the labels beagle and dachsund into a
dog class, you would specify the following for class_map:
{'dog': ['beagle', 'dachsund']}
Any labels not included in the dictionary will be left untouched.
One other use case for class_map is to deal with classification labels that
would be converted to float improperly. All Reader sub-classes use the
skll.data.readers.safe_float function internally to read labels. This function tries to
convert a single label first to int, then to float. If neither
conversion is possible, the label remains a str. Thus, care must be taken
to ensure that labels do not get converted in unexpected ways. For example,
consider the situation where there are classification labels that are a mixture
of int-converting and float-converting labels:
import numpy as np
from skll.data.readers import safe_float
np.array([safe_float(x) for x in ["2", "2.2", "2.21"]]) # array([2. , 2.2 , 2.21])
The labels will all be converted to floats and any classification model
generated with this data will predict labels such as 2.0, 2.2, etc.,
not str values that exactly match the input labels, as might be expected.
class_map could be used to map the original labels to new values that do
not have the same characteristics.
custom_learner_path (Optional)
Path to a .py file that defines a custom learner. This file will be
imported dynamically. This is only required if a custom learner is specified
in the list of learners.
All Custom learners must implement the fit and
predict methods. Custom classifiers must either (a) inherit from an existing scikit-learn classifier, or (b) inherit from both sklearn.base.BaseEstimator. and from sklearn.base.ClassifierMixin.
Similarly, Custom regressors must either (a) inherit from an existing scikit-learn regressor, or (b) inherit from both sklearn.base.BaseEstimator. and from sklearn.base.RegressorMixin.
Learners that require dense matrices should implement a method requires_dense
that returns True.
custom_metric_path (Optional)
Path to a .py file that defines a
custom metric function. This file will be imported dynamically. This is only required if a custom metric is specified as a
tuning objective, an output metric,
or both.
cv_seed (Optional)
The seed to use during the creation of the folds for the cross_validate task. This option may be useful for running the same cross validation experiment multiple times (with the same number of differently constituted folds) to get a sense of the variance across replicates.
Note that this seed is only used for shuffling the data before splitting it
into folds. The shuffling happens automatically when doing
grid search or if shuffle is explicitly
set to True. Defaults to 123456789.
feature_hasher (Optional)
If True, this enables a high-speed, low-memory vectorizer that uses
feature hashing for converting feature dictionaries into NumPy arrays
instead of using a
DictVectorizer. This flag will drastically
reduce memory consumption for data sets with a large number of
features. If enabled, the user should also specify the number of
features in the hasher_features field. For additional
information see the scikit-learn documentation.
Warning
Due to the way SKLL experiments are architected, if the features for an experiment are spread across multiple files on disk, feature hashing will be applied to each file separately. For example, if you have F feature files and you choose H as the number of hashed features (via hasher_features), you will end up with F x H features in the end. If this is not the desired behavior, use the join_features utility script to combine all feature files into a single file before running the experiment.
feature_scaling (Optional)
Whether to scale features by their mean and/or their standard deviation. If you scale by mean, your data will automatically be converted to dense, so use caution when you have a very large dataset. Valid options are:
- “none” or None
Perform no feature scaling at all.
- “with_std”
Scale feature values by their standard deviation.
- “with_mean”
Center features by subtracting their mean.
- “both”
Perform both centering and scaling.
The values are case insensitive. Defaults to “none”.
featureset_names (Optional)
Optional list of names for the feature sets. If omitted, then the prefixes will be munged together to make names.
folds_file (Optional)
Path to a csv file specifying the mapping of instances in the training data
to folds. This can be specified when the task is either train or
cross_validate. For the train task, if grid_search
is True, this file, if specified, will be used to define the
cross-validation used for the grid search (leave one fold ID out at a time).
Otherwise, it will be ignored.
For the cross_validate task, this file will be used to define the outer
cross-validation loop and, if grid_search is True, also for the
inner grid-search cross-validation loop. If the goal of specifiying the folds
file is to ensure that the model does not learn to differentiate based on a confound:
e.g. the data from the same person is always in the same fold, it makes sense to
keep the same folds for both the outer and the inner cross-validation loops.
However, sometimes the goal of specifying the folds file is simply for the
purpose of comparison to another existing experiment or another context
in which maintaining the constitution of the folds in the inner
grid-search loop is not required. In this case, users may set the parameter
use_folds_file_for_grid_search
to False which will then direct the inner grid-search cross-validation loop
to simply use the number specified via grid_search_folds
instead of using the folds file. This will likely lead to shorter execution times as
well depending on how many folds are in the folds file and the value
of grid_search_folds.
The format of this file must be as follows: the first row must be a header. This header row is ignored, so it doesn’t matter what the header row contains, but it must be there. If there is no header row, whatever row is in its place will be ignored. The first column should consist of training set IDs and the second should be a string for the fold ID (e.g., 1 through 5, A through D, etc.). If specified, the CV and grid search will leave one fold ID out at a time. [2]
fixed_parameters (Optional)
List of dictionaries containing parameters you want to have fixed for each
learner in the learners list. Empty dictionaries will be ignored
and the defaults will be used for these learners. If grid_search is True,
there is a potential for conflict with specified/default parameter grids
and fixed parameters.
Note
Tuples are not supported in the config file, and will lead to parsing errors. Make sure to replace tuples with lists when specifying fixed parameters. As an example, consider the following parameter that’s usually defined as a tuple in scikit-learn:
{'hidden_layer_sizes': (28, 28)}
To specify it in fixed_parameters, use a list instead:
{'hidden_layer_sizes': [28, 28]}
The default fixed parameters (beyond those that scikit-learn sets) are:
- AdaBoostClassifier and AdaBoostRegressor
{'n_estimators': 500, 'random_state': 123456789}
- BaggingClassifier and BaggingRegressor
{'n_estimators': 500, 'random_state': 123456789}
- DecisionTreeClassifier and DecisionTreeRegressor
{'random_state': 123456789}
- DummyClassifier
{'random_state': 123456789}
- ElasticNet
{'random_state': 123456789}
- GradientBoostingClassifier and GradientBoostingRegressor
{'n_estimators': 500, 'random_state': 123456789}
- HistGradientBoostingClassifier and HistGradientBoostingRegressor
{'random_state': 123456789}
- Lasso:
{'random_state': 123456789}
- LinearSVC and LinearSVR
{'random_state': 123456789}
- LogisticRegression
{'max_iter': 1000, 'multi_class': 'auto', 'random_state': 123456789, 'solver': 'liblinear'}
Note
The regularization
penaltyused by default is"l2". However,"l1","elasticnet", and"none"(no regularization) are also available. There is a dependency between thepenaltyand thesolver. For example, the"elasticnet"penalty can only be used in conjunction with the"saga"solver. See more information in thescikit-learndocumentation here.- MLPClassifier and MLPRegressor:
{'learning_rate': 'invscaling', 'max_iter': 500}
- RandomForestClassifier and RandomForestRegressor
{'n_estimators': 500, 'random_state': 123456789}
- RANSACRegressor
{'loss': 'squared_error', 'random_state': 123456789}
- Ridge and RidgeClassifier
{'random_state': 123456789}
- SVC and SVR
{'cache_size': 1000, 'gamma': 'scale'}
- SGDClassifier
{'loss': 'log', 'max_iter': 1000, 'random_state': 123456789, 'tol': 1e-3}
- SGDRegressor
{'max_iter': 1000, 'random_state': 123456789, 'tol': 1e-3}
- TheilSenRegressor
{'random_state': 123456789}
Note
The fixed_parameters field offers us a way to deal with imbalanced data sets by using the parameter
class_weightfor the following classifiers:DecisionTreeClassifier,LogisticRegression,LinearSVC,RandomForestClassifier,RidgeClassifier,SGDClassifier, andSVC.
Two possible options are available. The first one is balanced, which
automatically adjusts weights inversely proportional to class
frequencies, as shown in the following code:
{'class_weight': 'balanced'}
The second option allows you to assign a specific weight per each class. The default weight per class is 1. For example:
{'class_weight': {1: 10}}
Additional examples and information can be seen here.
hasher_features (Optional)
The number of features used by the FeatureHasher if the feature_hasher flag is enabled.
Note
To avoid collisions, you should always use the power of two larger than the number of features in the data set for this setting. For example, if you had 17 features, you would want to set the flag to 32.
id_col (Optional)
If you’re using ARFF, CSV, or TSV
files, the IDs for each instance are assumed to be in a column with this
name. If no column with this name is found, the IDs are generated
automatically. Defaults to id.
ids_to_floats (Optional)
If you have a dataset with lots of examples, and your input files have IDs that
look like numbers (can be converted by float()), then setting this to True will
save you some memory by storing IDs as floats. Note that this will cause IDs to
be printed as floats in prediction files (e.g., 4.0 instead of 4 or
0004 or 4.000).
label_col (Optional)
If you’re using ARFF, CSV, or TSV
files, the class labels for each instance are assumed to be in a column with
this name. If no column with this name is found, the data is assumed to be
unlabelled. Defaults to y. For ARFF files only, this must also be the final
column to count as the label (for compatibility with Weka).
learning_curve_cv_folds_list (Optional)
List of integers specifying the number of folds to use for cross-validation
at each point of the learning curve (training size), one per learner. For
example, specifying ["SVC", "LogisticRegression"] for learners
and specifying [10, 100] for learning_curve_cv_folds_list will
tell SKLL to use 10 cross-validation folds at each point of the SVC curve and
100 cross-validation folds at each point of the logistic regression curve. Although
more folds will generally yield more reliable results, smaller number of folds
may be better for learners that are slow to train. Defaults to 10 for
each learner.
learning_curve_train_sizes (Optional)
List of floats or integers representing relative or absolute numbers
of training examples that will be used to generate the learning curve
of training examples that will be used to generate the learning curve
respectively. If the type is float, it is regarded as a fraction of
the maximum size of the training set (that is determined by the selected
validation method), i.e. it has to be within (0, 1]. Otherwise it is
interpreted as absolute sizes of the training sets. Note that for classification
the number of samples usually has to be big enough to contain at least
one sample from each class. Defaults to [0.1, 0.325, 0.55, 0.775, 1.0].
num_cv_folds (Optional)
The number of folds to use for cross validation. Defaults to 10.
random_folds (Optional)
Whether to use random folds for cross-validation. Defaults to False.
sampler (Optional)
Whether to use a feature sampler that performs non-linear transformations of the input, which can serve as a basis for linear classification or other algorithms. Valid options are: Nystroem, RBFSampler, SkewedChi2Sampler, and AdditiveChi2Sampler. For additional information see the scikit-learn documentation.
Note
Using a feature sampler with the MultinomialNB learner is not allowed
since it cannot handle negative feature values.
sampler_parameters (Optional)
dict containing parameters you want to have fixed for the sampler.
Any empty ones will be ignored (and the defaults will be used).
The default fixed parameters (beyond those that scikit-learn sets) are:
- Nystroem
{'random_state': 123456789}
- RBFSampler
{'random_state': 123456789}
- SkewedChi2Sampler
{'random_state': 123456789}
shuffle (Optional)
If True, shuffle the examples in the training data before using them for
learning. This happens automatically when doing a grid search but it might be
useful in other scenarios as well, e.g., online learning. Defaults to
False.
suffix (Optional)
The file format the training/test files are in. Valid option are .arff, .csv, .jsonlines, .libsvm, .ndj, and .tsv.
If you omit this field, it is assumed that the “prefixes” listed in featuresets are actually complete filenames. This can be useful if you have feature files that are all in different formats that you would like to combine.
test_file (Optional)
Path to a file containing the features to test on. Cannot be used in combination with featuresets, train_directory, or test_directory
test_directory (Optional)
Path to directory containing test data files. There must be a file for each featureset. Cannot be used in combination with train_file or test_file.
Tuning
Generally, in this section, you would specify fields that pertain to the hyperparameter tuning for each learner. The most common required field is objectives although it may also be optional in certain circumstances.
objectives
A list of one or more metrics to use as objective functions for tuning the learner
hyperparameters via grid search. Note that objectives is required by default in most cases unless (a) grid_search is explicitly set to False or (b) the task is learning_curve. For (a), any specified objectives are ignored. For (b), specifying objectives will raise an exception.
SKLL provides the following metrics but you can also write your own custom metrics.
Classification: The following objectives can be used for classification problems although some are restricted by problem type (binary/multiclass), types of labels (integers/floats/strings), and whether they are contiguous (if integers). Please read carefully.
Note
When doing classification, SKLL internally sorts and maps all the class labels in the data and maps them to integers which can be thought of class indices. This happens irrespective of the data type of the original labels. For example, if your data has the labels
['A', 'B', 'C'], SKLL will map them to the indices[0, 1, 2]respectively. It will do the same if you have integer labels ([1, 2, 3]) or floating point ones ([1.0, 1.1, 1.2]). All of the tuning objectives are computed using these integer indices rather than the original class labels. This is why some metrics only make sense in certain scenarios. For example, SKLL only allows using weighted kappa metrics as tuning objectives if the original class labels are contiguous integers, e.g.,[1, 2, 3]or[4, 5, 6]– or even integer-like floats (e,g.,[1.0, 2.0, 3.0], but not[1.0, 1.1, 1.2]).
accuracy: Overall accuracy
average_precision: Area under PR curve . To use this metric, probability must be set to
True. (Binary classification only).balanced_accuracy: A version of accuracy specifically designed for imbalanced binary and multi-class scenarios.
f1: The default
scikit-learnF1 score (F1 of the positive class for binary classification, or the weighted average F1 for multiclass classification)f1_score_macro: Macro-averaged F1 score
f1_score_micro: Micro-averaged F1 score
f1_score_weighted: Weighted average F1 score
f1_score_least_frequent: F1 score of the least frequent class. The least frequent class may vary from fold to fold for certain data distributions.
f05: The default
scikit-learnFβ=0.5 score (Fβ=0.5 of the positive class for binary classification, or the weighted average Fβ=0.5 for multiclass classification)f05_score_macro: Macro-averaged Fβ=0.5 score
f05_score_micro: Micro-averaged Fβ=0.5 score
f05_score_weighted: Weighted average Fβ=0.5 score
jaccard: The default Jaccard similarity coefficient from
scikit-learnfor binary classification.jaccard_macro: Macro-averaged Jaccard similarity coefficient
jaccard_micro: Micro-averaged Jaccard similarity coefficient
jaccard_weighted: Weighted average Jaccard similarity coefficient
kendall_tau: Kendall’s tau . For binary classification and with probability set to
True, the probabilities for the positive class will be used to compute the correlation values. In all other cases, the labels are used. (Integer labels only).linear_weighted_kappa: Linear weighted kappa. (Contiguous integer labels only).
lwk_off_by_one: Same as
linear_weighted_kappa, but all ranking differences are discounted by one. (Contiguous integer labels only).neg_log_loss: The negative of the classification log loss . Since
scikit-learnrecommends using negated loss functions as scorer functions, SKLL does the same for the sake of consistency. To use this metric, probability must be set toTrue.pearson: Pearson correlation . For binary classification and with probability set to
True, the probabilities for the positive class will be used to compute the correlation values. In all other cases, the labels are used. (Integer labels only).precision: Precision for binary classification
precision_macro: Macro-averaged Precision
precision_micro: Micro-averaged Precision
precision_weighted: Weighted average Precision
quadratic_weighted_kappa: Quadratic weighted kappa. (Contiguous integer labels only). If you wish to compute quadratic weighted kappa for continuous values, you may want to use the implementation provided by RSMTool. To do so, install the RSMTool Python package and create a custom metric that wraps
rsmtool.utils.quadratic_weighted_kappa.qwk_off_by_one: Same as
quadratic_weighted_kappa, but all ranking differences are discounted by one. (Contiguous integer labels only).recall: Recall for binary classification
recall_macro: Macro-averaged Recall
recall_micro: Micro-averaged Recall
recall_weighted: Weighted average Recall
roc_auc: Area under ROC curve .To use this metric, probability must be set to
True. (Binary classification only).spearman: Spearman rank-correlation. For binary classification and with probability set to
True, the probabilities for the positive class will be used to compute the correlation values. In all other cases, the labels are used. (Integer labels only).unweighted_kappa: Unweighted Cohen’s kappa.
uwk_off_by_one: Same as
unweighted_kappa, but all ranking differences are discounted by one. In other words, a ranking of 1 and a ranking of 2 would be considered equal.
Regression: The following objectives can be used for regression problems.
explained_variance: A score indicating how much of the variance in the given data can be by the model.
kendall_tau: Kendall’s tau
linear_weighted_kappa: Linear weighted kappa (any floating point values are rounded to ints)
lwk_off_by_one: Same as
linear_weighted_kappa, but all ranking differences are discounted by one.max_error: The maximum residual error.
neg_mean_absolute_error: The negative of the mean absolute error regression loss. Since
scikit-learnrecommends using negated loss functions as scorer functions, SKLL does the same for the sake of consistency.neg_mean_squared_error: The negative of the mean squared error regression loss. Since
scikit-learnrecommends using negated loss functions as scorer functions, SKLL does the same for the sake of consistency.neg_root_mean_squared_error: The negative of the mean squared error regression loss, with
squaredset to False. Sincescikit-learnrecommends using negated loss functions as scorer functions, SKLL does the same for the sake of consistency.pearson: Pearson correlation
quadratic_weighted_kappa: Quadratic weighted kappa (any floating point values are rounded to ints)
qwk_off_by_one: Same as
quadratic_weighted_kappa, but all ranking differences are discounted by one.r2: R2
spearman: Spearman rank-correlation
unweighted_kappa: Unweighted Cohen’s kappa (any floating point values are rounded to ints)
uwk_off_by_one: Same as
unweighted_kappa, but all ranking differences are discounted by one. In other words, a ranking of 1 and a ranking of 2 would be considered equal.
The following is a list of the other optional fields in this section in alphabetical order.
grid_search (Optional)
Whether or not to perform grid search to find optimal parameters for
the learner. Defaults to True since optimizing model hyperparameters
almost always leads to better performance. Note that for the
learning_curve task, grid search is not allowed
and setting it to True will generate a warning and be ignored.
Note
In versions of SKLL before v2.0, this option was set to
Falseby default but that was changed since the benefits of hyperparameter tuning significantly outweigh the cost in terms of model fitting time. Instead, SKLL users must explicitly opt out of hyperparameter tuning if they so desire.Although SKLL only uses the combination of hyperparameters in the grid that maximizes the grid search objective, the results for all other points on the grid that were tried are also available. See the
grid_search_cv_resultsattribute in the.results.jsonfile.
grid_search_folds (Optional)
The number of folds to use for grid search. Defaults to 5.
grid_search_jobs (Optional)
Number of folds to run in parallel when using grid search. Defaults to number of grid search folds.
min_feature_count (Optional)
The minimum number of examples for which the value of a feature must be nonzero to be included in the model. Defaults to 1.
param_grids (Optional)
List of parameter grid dictionaries, one for each learner. Each parameter grid is a dictionary mapping from strings to list of parameter values. When you specify an empty dictionary for a learner, the default parameter grid for that learner will be searched.
The default parameter grids for each learner are:
- AdaBoostClassifier and AdaBoostRegressor
{'learning_rate': [0.01, 0.1, 1.0, 10.0, 100.0]}
- BaggingClassifier and BaggingRegressor
{'max_samples': [0.1, 0.25, 0.5, 1.0], 'max_features': [0.1, 0.25, 0.5, 1.0]}
- BayesianRidge
{'alpha_1': [1e-6, 1e-4, 1e-2, 1, 10], 'alpha_2': [1e-6, 1e-4, 1e-2, 1, 10], 'lambda_1': [1e-6, 1e-4, 1e-2, 1, 10], 'lambda_2': [1e-6, 1e-4, 1e-2, 1, 10]}
- DecisionTreeClassifier and DecisionTreeRegressor
{'max_features': ["sqrt", None]}
- ElasticNet
{'alpha': [0.01, 0.1, 1.0, 10.0, 100.0]}
- GradientBoostingClassifier and GradientBoostingRegressor
{'max_depth': [1, 3, 5]}
- HistGradientBoostingClassifier
{'learning_rate': [0.01, 0.1, 1.0], 'min_samples_leaf': [10, 20, 40]}
- HistGradientBoostingRegressor
{'loss': ['squared_error', 'absolute_error', 'poisson'], 'learning_rate': [0.01, 0.1, 1.0], 'min_samples_leaf': [10, 20, 40]}
- HuberRegressor
{'epsilon': [1.05, 1.35, 1.5, 2.0, 2.5, 5.0], 'alpha': [1e-4, 1e-3, 1e-3, 1e-1, 1, 10, 100, 1000]}
- KNeighborsClassifier and KNeighborsRegressor
{'n_neighbors': [1, 5, 10, 100], 'weights': ['uniform', 'distance']}
- Lasso
{'alpha': [0.01, 0.1, 1.0, 10.0, 100.0]}
- LinearSVC
{'C': [0.01, 0.1, 1.0, 10.0, 100.0]}
- LogisticRegression
{'C': [0.01, 0.1, 1.0, 10.0, 100.0]}
- MLPClassifier and MLPRegressor:
{'activation': ['logistic', 'tanh', 'relu'], 'alpha': [1e-4, 1e-3, 1e-3, 1e-1, 1], 'learning_rate_init': [0.001, 0.01, 0.1]},
- MultinomialNB
{'alpha': [0.1, 0.25, 0.5, 0.75, 1.0]}
- RandomForestClassifier and RandomForestRegressor
{'max_depth': [1, 5, 10, None]}
- Ridge and RidgeClassifier
{'alpha': [0.01, 0.1, 1.0, 10.0, 100.0]}
- SGDClassifier and SGDRegressor
{'alpha': [0.000001, 0.00001, 0.0001, 0.001, 0.01], 'penalty': ['l1', 'l2', 'elasticnet']}
- SVC
{'C': [0.01, 0.1, 1.0, 10.0, 100.0], 'gamma': ['auto', 0.01, 0.1, 1.0, 10.0, 100.0]}
- SVR
{'C': [0.01, 0.1, 1.0, 10.0, 100.0]}
Note
Learners not listed here do not have any default parameter grids in SKLL either because there are no hyper-parameters to tune or decisions about which parameters to tune (and how) depend on the data being used for the experiment and are best left up to the user.
Tuples are not supported in the config file, and will lead to parsing errors. Make sure to replace tuples with lists when specifying fixed parameters. As an example, consider the following parameter that’s usually defined as a tuple in scikit-learn:
{'hidden_layer_sizes': (28, 28)}To specify it in param_grids, use a list instead:
{'hidden_layer_sizes': [28, 28]}
pos_label (Optional)
A string denoting the label of the class to be
treated as the positive class in a binary classification
setting. If unspecified, the class represented by the label
that appears second when sorted is chosen as the positive
class. For example, if the two labels in data are “A” and
“B” and pos_label is not specified, “B” will be chosen
as the positive class.
use_folds_file_for_grid_search (Optional)
Whether to use the specified folds_file for the inner grid-search
cross-validation loop when task is set to cross_validate.
Defaults to True.
Note
This flag is ignored for all other tasks, including the
train task where a specified folds_file is
always used for the grid search.
Output
The fields in this section generally pertain to the
output files produced
by the experiment. The most common fields are logs, models,
predictions, and results. These fields are mostly optional
although they may be required in certain cases. A common option
is to use the same directory for all of these fields.
logs (Optional)
Directory to store SKLL log files in. If omitted, the current working directory is used.
models (Optional)
Directory in which to store trained models. Can be omitted to not store models except when using the train task, where this path must be specified. On the other hand, this path must not be specified for the learning_curve task.
metrics (Optional)
For the evaluate and cross_validate tasks, this is an optional
list of additional metrics that will be computed in addition to
the tuning objectives and added to the results files. However, for the
learning_curve task, this list is required.
Possible values are all of the same functions as those available for the
tuning objectives (with the same caveats).
As with objectives, You can also use your own custom metric functions.
Note
If the list of metrics overlaps with the grid search tuning
objectives, then, for each job, the objective
that overlaps is not computed again as a metric. Recall that
each SKLL job can only contain a single tuning objective. Therefore,
if, say, the objectives list is ['accuracy', 'roc_auc'] and the
metrics list is ['roc_auc', 'average_precision'], then in the
second job, roc_auc is used as the objective but not computed
as an additional metric.
pipeline (Optional)
Whether or not the final learner object should contain a pipeline
attribute that contains a scikit-learn Pipeline object composed
of copies of each of the following steps of training the learner:
feature vectorization (vectorizer)
feature selection (selector)
feature sampling (sampler)
feature scaling (scaler)
main estimator (estimator)
The strings in the parentheses represent the name given to each step in the pipeline.
The goal of this attribute is to allow better interoperability
between SKLL learner objects and scikit-learn. The user can
train the model in SKLL and then further tweak or analyze
the pipeline in scikit-learn, if needed. Each component of the
pipeline is a (deep) copy of the component that was fit as part
of the SKLL model training process. We use copies since we do
not want the original SKLL model to be affected if the user
modifies the components of the pipeline in scikit-learn space.
Here’s an example of how to use this attribute.
from sklearn.preprocessing import LabelEncoder
from skll.data import Reader
from skll.learner import Learner
# train a classifier and a regressor using the SKLL API
fs1 = Reader.for_path('examples/iris/train/example_iris_features.jsonlines').read()
learner1 = Learner('LogisticRegression', pipeline=True)
_ = learner1.train(fs1, grid_search=True, grid_objective='f1_score_macro')
fs2 = Reader.for_path('examples/california/train/example_california_features.jsonlines').read()
learner2 = Learner('RescaledSVR', feature_scaling='both', pipeline=True)
_ = learner2.train(fs2, grid_search=True, grid_objective='pearson')
# now, we can explore the stored pipelines in sklearn space
enc = LabelEncoder().fit(fs1.labels)
# first, the classifier
D1 = {"f0": 6.1, "f1": 2.8, "f2": 4.7, "f3": 1.2}
pipeline1 = learner1.pipeline
enc.inverse_transform(pipeline1.predict(D1))
# then, the regressor
D2 = {"f0": 4.1344, "f1": 36.0, "f2": 4.1, "f3": 0.98, "f4": 1245.0, "f5": 3.0, "f6": 33.9, "f7": -118.32}
pipeline2 = learner2.pipeline
pipeline2.predict(D2)
# note that without the `pipeline` attribute, one would have to
# do the following for D1, which is much less readable
enc.inverse_transform(learner1.model.predict(learner1.scaler.transform(learner1.feat_selector.transform(learner1.feat_vectorizer.transform(D1)))))
Note
When using a DictVectorizer in SKLL along with feature_scaling set to either
with_meanorboth, the sparse attribute of the vectorizer stage in the pipeline is set toFalsesince centering requires dense arrays.When feature hashing is used (via a FeatureHasher ) in SKLL along with feature_scaling set to either
with_meanorboth, a custom pipeline stage (skll.learner.Densifier) is inserted in the pipeline between the feature vectorization (here, hashing) stage and the feature scaling stage. This is necessary since aFeatureHasherdoes not have asparseattribute to turn off – it only returns sparse vectors.A
Densifieris also inserted in the pipeline when using a SkewedChi2Sampler for feature sampling since this sampler requires dense input and cannot be made to work with sparse arrays.
predictions (Optional)
Directory in which to store prediction files. Must not be specified for the learning_curve and train tasks. If omitted, the current working directory is used.
probability (Optional)
Whether or not to output probabilities for each class instead of the
most probable class for each instance. Only really makes a difference
when storing predictions. Defaults to False. Note that this also
applies to the tuning objective.
results (Optional)
Directory in which to store result files. If omitted, the current working directory is used.
save_cv_folds (Optional)
Whether to save the folds file containing the folds for a cross-validation experiment.
Defaults to True.
save_cv_models (Optional)
Whether to save each of the K model files trained during
each step of a K-fold cross-validation experiment.
Defaults to False.
save_votes (Optional)
Whether to save the predictions from the individual estimators underlying a
VotingClassifer or VotingRegressor. Note that for this to work,
predictions must be set.
Defaults to False.
wandb_credentials (Optional)
To enable logging metrics and artifacts to Weights & Biases, specify a dictionary as follows:
{'wandb_entity': 'your_entity_name', 'wandb_project': 'your_project_name'}
wandb_entity can be a user name or the name of a team or organization.
wandb_project is the name of the project to which this experiment will be logged.
If a project by this name does not already exist, it will be created.
For more details on what will be logged, and an example report, see Integration with Weights & Biases.
Important
Both wandb_entity and wandb_project must be specified. If any of them is missing, logging to W&B will not be enabled.
Before using Weights & Biases for the first time, users should log in and provide their API key as described in W&B Quickstart guidelines.
Note that when using W&B logging, a SKLL run may take significantly longer due to the network traffic being sent to W&B.
Using run_experiment
Once you have created the configuration file for your
experiment, you can usually just get your experiment started by running
run_experiment CONFIGFILE. [3] That said, there are a few options that are
specified via command-line arguments instead of in the configuration file:
- -a <num_features>, --ablation <num_features>
Runs an ablation study where repeated experiments are conducted with the specified number of feature files in each featureset in the configuration file held out. For example, if you have three feature files (
A,B, andC) in your featureset and you specifiy--ablation 1, there will be three experiments conducted with the following featuresets:[[A, B], [B, C], [A, C]]. Additionally, since every ablation experiment includes a run with all the features as a baseline, the following featureset will also be run:[[A, B, C]].If you would like to try all possible combinations of feature files, you can use the
run_experiment --ablation_alloption instead.Warning
Ablation will not work if you specify a train_file and test_file since no featuresets are defined in that scenario.
- -A, --ablation_all
Runs an ablation study where repeated experiments are conducted with all combinations of feature files in each featureset.
Warning
This can create a huge number of jobs, so please use with caution.
- -k, --keep-models
If trained models already exist for any of the learner/featureset combinations in your configuration file, just load those models and do not retrain/overwrite them.
- -r, --resume
If result files already exist for an experiment, do not overwrite them. This is very useful when doing a large ablation experiment and part of it crashes.
- -v, --verbose
Print more status information. For every additional time this flag is specified, output gets more verbose.
- --version
Show program’s version number and exit.
GridMap options
If you have GridMap installed, run_experiment will automatically schedule jobs on your DRMAA- compatible cluster. You can use the following options to customize this behavior.
- -m <machines>, --machines <machines>
Comma-separated list of machines to add to GridMap’s whitelist. If not specified, all available machines are used.
Note
Full names must be specified, (e.g.,
nlp.research.ets.org).
Output files
For most of the SKLL tasks the various output files generated by run_experiment share the automatically generated prefix
<EXPERIMENT>_<FEATURESET>_<LEARNER>_<OBJECTIVE>, where the following definitions hold:
<EXPERIMENT>The value of the experiment_name field in the configuration file.
<FEATURESET>The components of the feature set that was used for training, joined with “+”.
<LEARNER>The learner that was used to generate the current results/model/etc.
<OBJECTIVE>The objective function that was used to generate the current results/model/etc.
Note
In SKLL terminology, a specific combination of featuresets, learners,
and objectives specified in the configuration file is called a job.
Therefore, an experiment (represented by a configuration file) can
contain multiple jobs.
However, if the objectives field in the configuration file
contains only a single value, the job can be disambiguated using only
the featuresets and the learners since the objective is fixed. Therefore,
the output files will have the prefix <EXPERIMENT>_<FEATURESET>_<LEARNER>.
Similarly, if a task has a single feature set, the output
files prefix will not include the <FEATURESET> component.
The following types of output files can be generated after running an experiment configuration file through run_experiment. Note that some file types may or may not be generated depending on the values of the fields specified in the Output section of the configuration file.
Log files
SKLL produces two types of log files – one for each job in the experiment
and a single, top level log file for the entire experiment. Each of the job
log files have the usual job prefix as described above whereas the experiment
log file is simply named <EXPERIMENT>.log.
While the job-level log files contain messages that pertain to the specific
characteristics of the job (e.g., warnings from scikit-learn pertaining to
the specific learner), the experiment-level log file will contain logging
messages that pertain to the overall experiment and configuration file (e.g.,
an incorrect option specified in the configuration file). The messages in all
SKLL log files are in the following format:
<TIMESTAMP> - <LEVEL> - <MSG>
where <TIMESTAMP> refers to the exact time when the message was logged,
<LEVEL> refers to the level of the logging message (e.g., INFO, WARNING,
etc.), and <MSG> is the actual content of the message. All of the messages
are also printed to the console in addition to being saved in the job-level log
files and the experiment-level log file.
Model files
Model files end in .model and are serialized skll.learner.Learner
instances. run_experiment will re-use existing model
files if they exist, unless it is explicitly told not to. These model files
can also be loaded programmatically via the SKLL API, specifically the
skll.learner.Learner.from_file() method.
Results files
SKLL generates two types of result files:
Files ending in
.resultswhich contain a human-readable summary of the job, complete with confusion matrix, objective function score on the test set, and values of any additional metrics specified via the metrics configuration file option.Files ending in
.results.json, which contain all of the same information as the.resultsfiles, but in a format more well-suited to automated processing. In some cases,.results.jsonfiles may contain more information than their.resultsfile counterparts. For example, when doing grid search for tuning model hyperparameters, these files contain an additional attributegrid_search_cv_resultscontaining detailed results from the grid search process.
Prediction files
Predictions files are TSV files that contain either the predicted values (for regression) OR predicted labels/class probabiltiies (for classification) for each instance in the test feature set. The value of the probability option decides whether SKLL outputs the labels or the probabilities.
When the predictions are labels or values, there are only two columns in the file: one containing the ID for the instance and the other containing the prediction. The headers for the two columns in this case are “id” and “prediction”.
When the predictions are class probabilities, there are N+1 columns in these files, where N is the number of classes in the training data. The header for the column containing IDs is still “id” and the labels themselves are the headers for the columns containing their respective probabilities. In the special case of binary classification, the positive class probabilities are always in the last column.
Summary file
For every experiment you run, there will also be an experiment summary file
generated that is a tab-delimited file summarizing the results for each
job in the experiment. It is named <EXPERIMENT>_summary.tsv.
For learning_curve experiments, this summary
file will contain training set sizes and the averaged scores for all
combinations of featuresets, learners, and objectives.
Folds file
For the cross_validate task, SKLL can also output
the actual folds and instance IDs used in the cross-validation process, if
the save_cv_folds option is enabled. In this case,
a file called <EXPERIMENT>_skll_fold_ids.csv is saved to disk.
Learning curve plots
When running a learning_curve experiment,
actual learning curves are also generated as .png files. Two curves are generated
for each feature set specified in the configuration file.
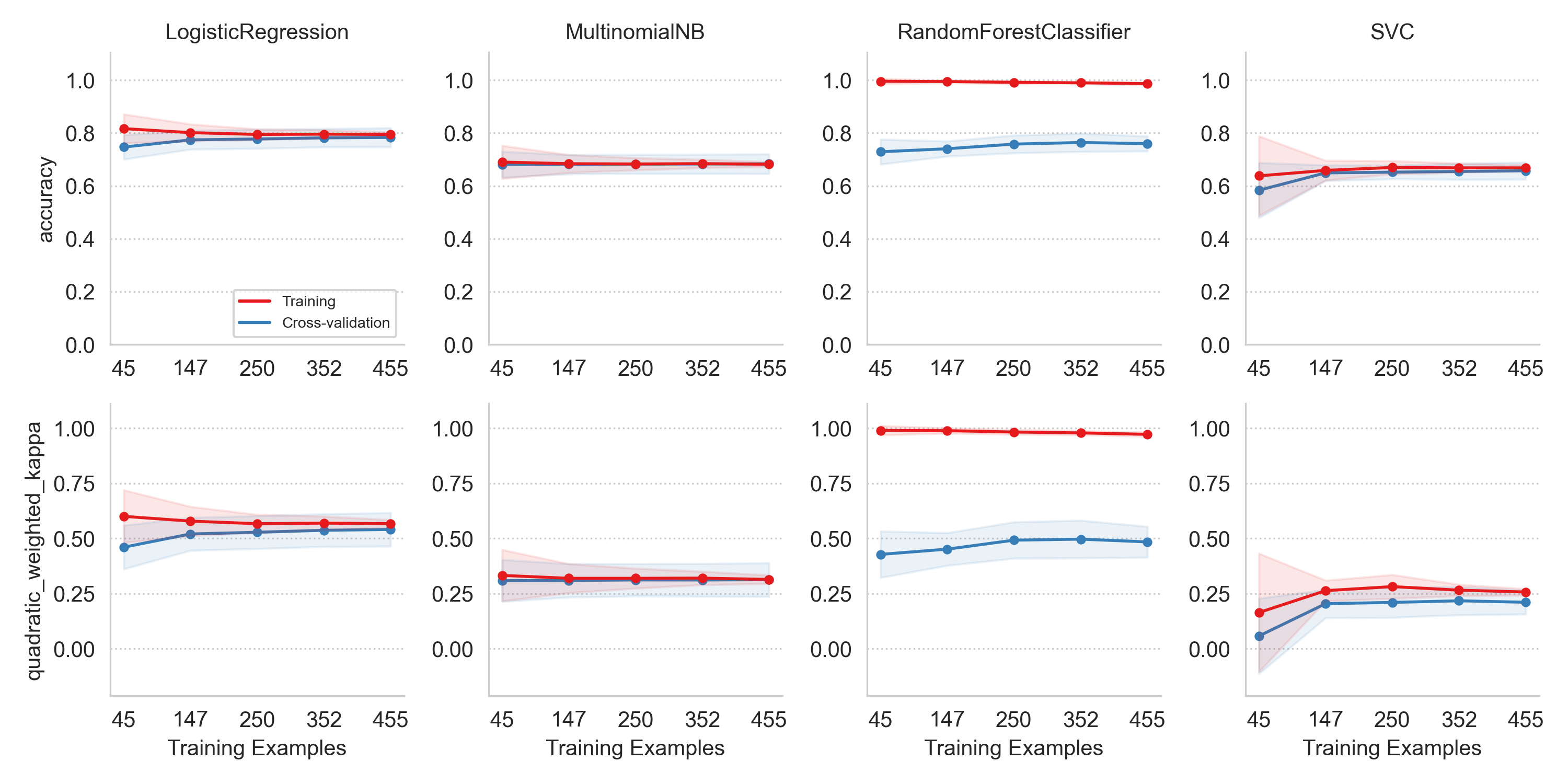
The first .png file is named EXPERIMENT_FEATURESET.png
and contains a double-faceted learning curve plot for the featureset with the
specified output metrics along the rows and the
learners along the columns. Each sub-plot has the number of training
examples on the x-axis and the metric score on the y-axis. Here’s an example
of such a plot.
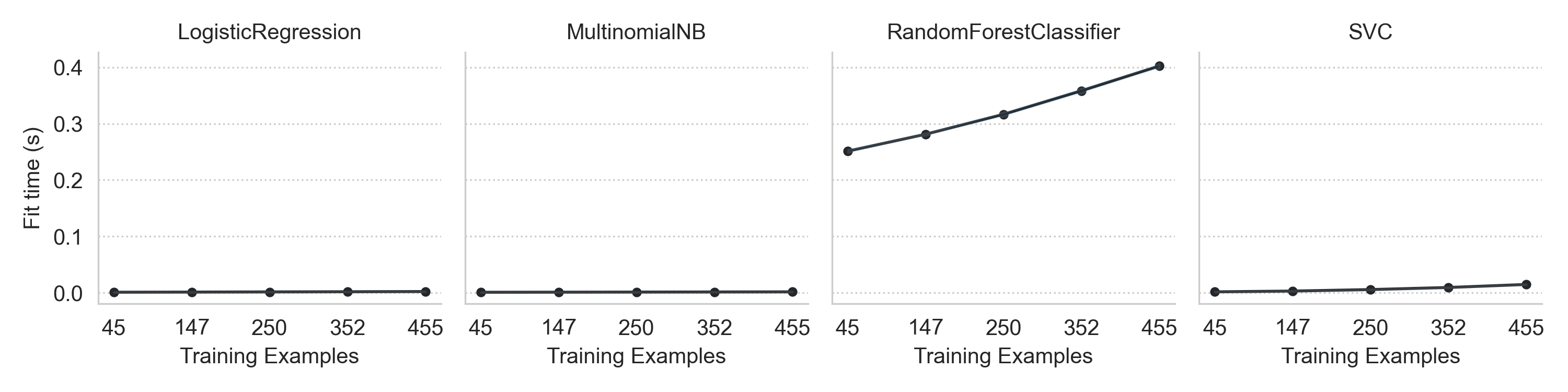
The second .png file is named EXPERIMENT_FEATURESET_times.png
and contains a column-faceted learning curve plot for the featureset with a single
row and the specified learners along the columns. Each sub-plot has the
number of training examples on the x-axis and the model fit times on the y-axis.
Here’s an example of this plot.
You can also generate the plots from the learning curve summary file using the plot_learning_curves utility script.
Integration with Weights & Biases
The output of any SKLL experiment can be automatically logged to Weights & Biases. Once the logging is enabled, a new run will be created under the specified W&B project. The following is logged for all tasks:
The SKLL configuration file, including default values for fields that were left unspecified
The learner, feature set, and size of training and testing sets for each job in the experiment
- There are additional items logged depending on the task type:
train: The full path to the generated model file is logged in the project summary.
predict: The predictions file is logged as a table, separately for each job in the experiment.
evaluate: The task summary file is logged as a table. For classification experiments, the confusion matrix as well as a table that shows per-label precision, recall and f-measure are logged for each job.
cross_validate: Similar output logged as the evaluate task, with a separate job per CV fold.
learning_curve The summary file is logged as a table, and all learning curve plots are logged as media artifacts.
The above information logged to Weights & Biases can then be used to create informative reports for your SKLL experiments. As an example, here is a report created on Weights & Biases, based on the data logged while running the titanic tutorial. The report contains three sections, one per SKLL task, with a subset of the output tables and metrics that were logged for each of the tasks.
To view the full output and create your own reports, turn on logging to Weights and Biases
in the configuration Output section.
Footnotes